CPDA那些事|上海37期大数据沙龙回顾三
四. 数据分析案例分享
4.1 老生常谈RFM客户价值分析
当具备了基本的分析能力以后,你就会开始去寻找数据分析的方法论,而且同时你还会徘徊在业务适用与理论结论的矛盾之间。
为了便于描述这种现象,我拿RFM客户价值分析举例。
参加过CPDA培训的人或者数据分析的爱好者对RFM模型并不生疏,因为它是由统计方法衍生出来的,所以很多工具都能实现,很多工具书中都会有记载,所以很多人都能够快速上手。(现场就如何使用RFM客户价值分析做了简要说明)
值得注意的是,当理论的结论不适用我们时,我们是否具有勇气,尝试组合方法。毕竟组合方法存在一定的争议,又不被知名人士验证,所以不同的人可能会有不同的看法,所以显然会被告知不严谨。
我们看看PPT中右边的方法:与原理不一样的地方是,在进行数据标准化以后,我们进行了聚类,加了聚类算法能够很好的帮助我们根据某个目标目的将数据进行分类,这里加入聚类就是为了能够更好的帮助我们进行群的分类。在分类完成后,我们才会基于群的均值去判断客户所处的网络位置和价值得分,还有群间的对比,最后输出结果。因为客户是在群中比较的,所以也显得相对公平。
显然后者的方法看起来更符合业务使用,但会存在争议。
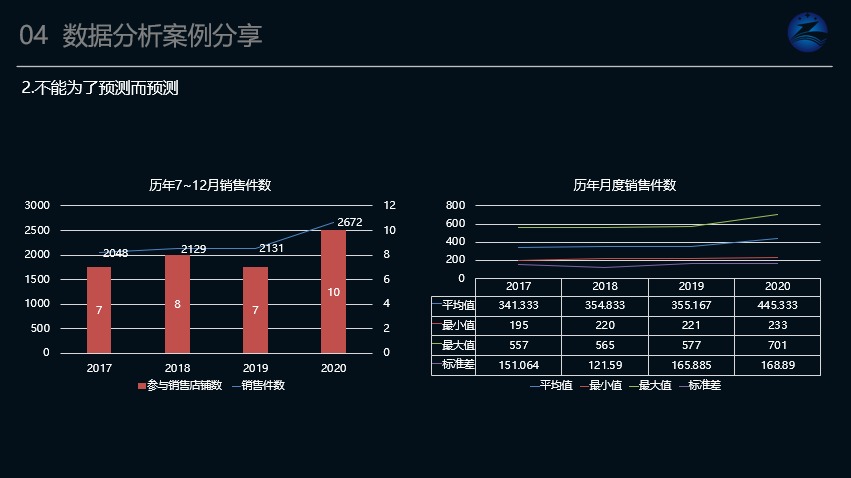
有人问:当我们知道了某货品的近3年每月销售量情况,请预测该货品2021年7~12月销量总和时,我们该如何去做预测?
也许有人会说:可以通过时间序列搞搞,也许有人会说通过环比同比综合判断,也会有人说通过回归算法算算等等。
可以跟大家分享一下,当我遇到这道题时的做法:当我遇到这个问题时,我首先会跳出预测所为我设计的路线。我不会问自己这种业务用哪种算法合适,而是会先问自己,在这个场景下,预测的本质是什么?是求附加参考值,还是目标范围值,还是概率发生值。
只要当你明确了你所想要的结果,那么你就知道你所要采取的方法,这里我想着是求一个附加参考值,毕竟目标值业务已经基于常态决策思路初步锁定。
竟然业务已经锁定目标值,那么在知识有差异的前提下,贸然采用算法去计算,业务也很难理解,于是我对所要求的结果定义为求附加参考值,所以我就没有把它当成算法题来看待,而是把它当成数组题来看待。
转为数据来看待后,其实就得看每年的结果的形成(也就是月度指标)是否稳定,如果每月的指标相对稳定,那么那年的值是具备参考意义的。
经统计发现对比,形成了右侧的结果。透过标准差、最大最小值、平均值来看历年值的稳定程度,综合得知2018年的值是较具有参考意义的。
假如非得用算法去计算,其实也可以,比如说用时间序列算法,那就把季节影响的考虑给排除,只取同结果月份一样的数据进行计算,这样子也会求得一个附加参考值。
当你具备了基本分析能力,你就会想着在企业中能有更大的发挥空间,那么基于这种情况,我们小结了一下,可以从这4点突破,也是许多企业家比较乐于见到的。
第一点就是要使企业内的各部门人员,更高效的观察数据,我们可以通过各种数据分析工具,去建立模型,让人员不用在做表,优化他们的时间,让他们能够有更多的时间在做决策上,在做业务分析上。
当完成了第一点,你就会收获来自于团队的信任,你就可以对业务进行进一步了解。可以通过协助某业务部门做关键指标的异动查因,然后找出规律,提供尝试办法。当小办法获得验证后,可以顺着了解更多的关键指标,去理解业务思维中所理解的指标本质,而此时因为进一步的信任,你会与业务沟通更加紧密,你有发现告诉他,他描述不清晰的地方也会补充告知你。
当完成了前两项,你会收到更重要的任务,就是开始对一些策略进行评估。而此时你也不需要太过于担心,只要基于业务经验的基础上,融入数理进行科学约束步骤,量化过程即可。
当完成几个策略评估后,对于在公司中建立立体化的运营管理体系,就会了然于胸了。
当然,想要完成这些,我们势必需要借助工具进行实现,在没有技术的支持下,除了SQL、python等技术语言,我们建议可以通过kettle去做ETL,做数据处理方面的工作,也可以通过IBM Spss Modeler来进行数据挖掘,最后通过PowerBI来搭建报表服务器,制作内外网访问的网页端、APP端的数据可视化作品。
我们在给企业制定过渡解决方案时,会通过这些工具来进行处理事务,只有当业务明确后,才会去写脚本,去用技术语言构建模型与程序。
周师兄满满正能量的干货分享,可以直接扫码观看回放(回看截止日期为2021年1月21日,抓紧时间哦!)