上海交通大学教授金耀辉:AI在智慧法院中的应用
2017年11月10日,由上海大数据联盟、数据猿主办,上海科睿联合主办的《构建智慧法院,促进司法职能——魔方大数据》在上海超级计算机中心举行。本期魔方大数据邀请了法院代表和技术提供方等专家大咖齐聚一堂,共同探讨了智慧法院和司法系统智能化的建设之路。
以下是数据猿整理“上海交通大学教授金耀辉”的发言实录:
人工智能领域目前在中国被炒的火热,在司法领域也实现了初步实践。正如前不久李开复在美国演讲时提到,中国很有可能在AI上面实现弯道超车。
我们今天讲的是智慧法院,在美国,人工智能在司法服务方面覆盖了很多场景,包括知识产权、尽职调查、法律分析、预测技术、司法研究、流程自动、电子商务等等,每年大概能达到400多亿美元。然而与其他行业相比,这个数字并不算多,因为400多亿仅占到整个司法服务的3%到4%。我们认为人工智能应用应该能达到5%到6%之间,因此这个市场依然还有巨大的空间,在中国估计这个市场会更大。
人工智能到底是什么?人工智能究竟能够帮助我们做什么?我相信大家都会有这样的疑惑。人工智能从研究领域到应用领域,我们希望的是能用机器来辅助人做一些决断或者推荐。整个机器学习的框架摆在这里,我们拥有原始数据,这里的原始数据可以理解为是客观数据,比如医院的检查或者法院的收案、结案等。同时还有一些业务数据,即跟具体的业务相关,比方说在医院里面诊断了是癌症或者不是癌症。然后进行算法学习、模型评估,最后是预测,比如在法院可以预测某个案子的胜率是多少。
现在“阿尔法狗”非常火,因此很多人一讲到人工智能就讲深度学习,事实上,深度学习只是人工智能的一种。在过去不是说没有人工智能,其实早在很多场景下我们已经开始使用了,只不过当时我们称其为规则的系统。比如在法院里面,犯了什么罪、要判几年刑,这就是规则。再往后机器学习会把这些特征找到,由机器去做映射,越到机器部分,效率会越好、准确度会提升,但是可解释性是下降的,这也是我们所面临的一个巨大难题。往往我们做出来一个模型,做得很好,效率很高,但是为什么会识别出来,我们并不知道,也就是说这个模型是一个黑箱。
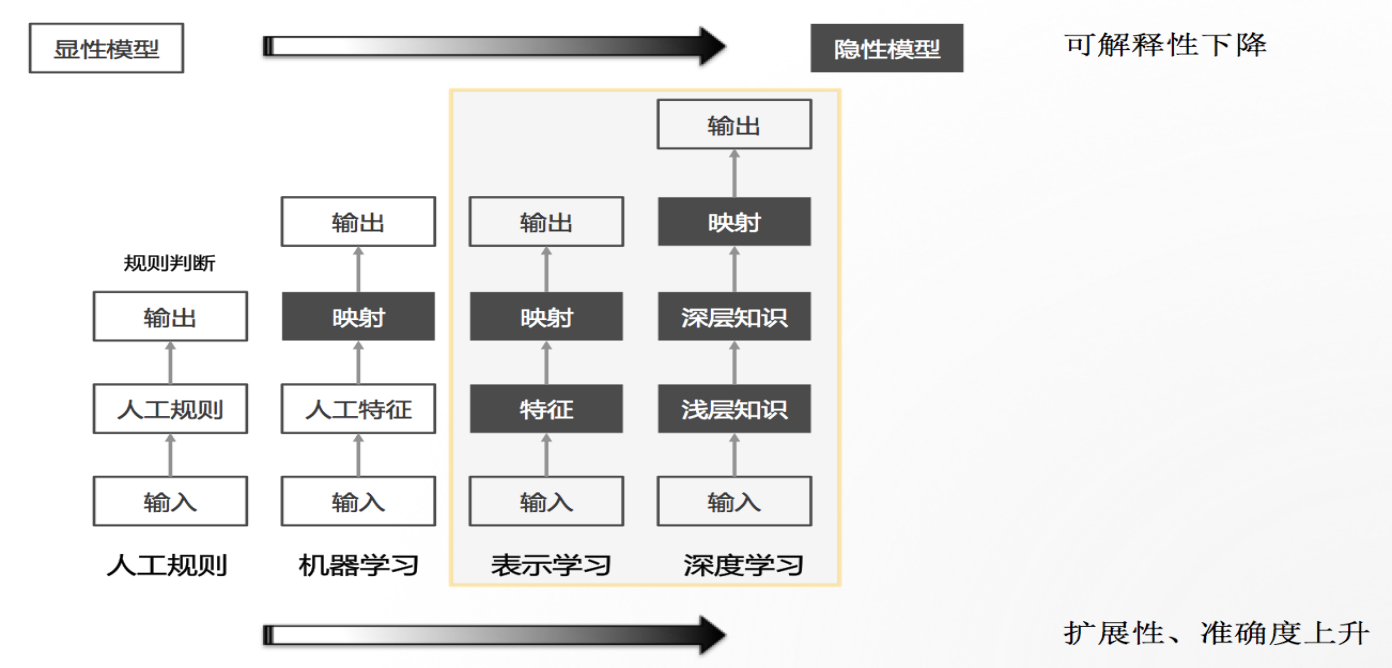
人工智能应用在司法领域不仅仅是人工智能,它更是一种可为洞察,也就是给利益攸关者一些建议。什么叫可为洞察,我们是研究者,我们会把各种各样的数据,比如说法院内部的数据和外部的数据集成起来。那么这些数据为谁服务呢?过去做个大屏给领导展示一下,这是为管理者服务;还有就是给执行者服务,中国一线法官他面临的问题是案多人少,当他想查到一些类案的时候,其实并不方便,这时候人工智能就能为他们服务;最后是为当事人服务。
在整个社会管理领域,我们提倡3D持续改进,首先是DATA,前面讲到模型在决策中起了关键的作用,确实是这样。今年MIT有一个专业报道讲的是人工智能最核心的秘密。最核心的秘密就是我们建立了很多模型,这个模型精确度检测得很好,但是我们不知道为什么工作。以文本来说,我们可以把很多非结构化数据放到里面,并输出数据。但是我们经常会被质疑,问我们数据是怎么得到的?我不知道。我们在跟自贸区合作的时候,第一次尝试用深度学习,我们预测了4000多个P2P平台,预测它下个月会不会倒,准确率有85%。但是金融监管部门不敢用,因为它觉得我们的模型不可解释,不符合它的逻辑。包括在做类案的时候,跟法院的沟通也是这样,他让我们解释这个模型到底是怎么预测的,说不清楚就不敢用。因此这个问题困扰了我们很长时间。
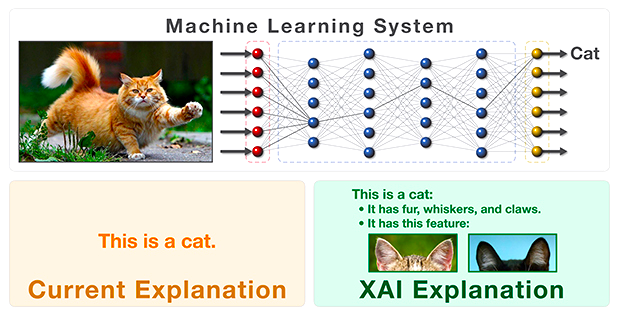
什么叫人工智能?大家可以看到,上图是一张猫的图像,我们可以用深度学习识别出来图片上呈现的是一只猫,而且准确度非常高。人在识别猫的时候,由于猫有耳朵、皮毛、尾巴,所以知道这是猫。识别狗的时候也是这样,狗也有尾巴,但是狗的尾巴短,人是这样解释的。但如果用这样一个可解释的过程,你会发现当黑盒变成了灰盒或者白盒以后,它的准确度在下降。所以把刚才的过程加上了模糊的逻辑(之所以是模糊的,是因为人的很多知识是描绘不清楚的),经过特征生成、监督泛化、学习推理,最后形成业务逻辑。我们可解释以后,准确度在下降,这也不行。
那怎么办?我们在这个过程中间,加入了“错误分析”,可通过不断的迭代优化使得它分析的准确度再提升。但是在这个过程中,因为机器的能力是海量的,你不能让人去验证,这就给算法带来了一些挑战。我们要思考的是人和机器该怎么去融合,因此我们提出了名为元思的机器平台,它是一个深度学习框架与人机融合平台,很多机器学习算法都可以适用到这里面。
下面回到类案,我们一直被质疑,究竟什么是类案?我们查阅了很多资料,也跟很多专业老师沟通过,我觉得北大法学院的教授讲的是可以令人信服的:
第一,案件的关键事实相似;
第二,案件的裁判要点相似。
文章中讲到的类案分析用的都是专业的法律术语,搞懂其中隐含的法律逻辑判断过程,人看懂都是一件费力的事情,分析清楚其中的逻辑更是难上加难。如此复杂的语义逻辑试图让机器看懂,这其中的困难可想而知。所以我们的问题就是,怎么用机器做自动化的类案,也就是类案识别,这是一个最核心的问题。
一份裁判文书都有它的规范,从当事人、当庭的质证到最后的判决,我们要从结构上让计算机能读懂。首先法律的逻辑是什么?你有一个诉讼,这里指的是民案,你有诉讼请求,有证据的认定,认定以后有案件的事实,有争议的焦点,有因果关系,有适用法律,最后有判决结果。将这些东西形成案件图谱,在图谱上进行比较,这样的表达计算机能读懂,这是关键。通过这样一个模式,在保证准确度的前提下提升了司法的可解释性,这也就是我们在司法领域所研究的可解释的人工智能。
作为可解释的人工智能就是不仅仅要知其然,更要知其所以然,是可解释的。我们讲机器可以辅助法官办案,参与迭代的时候我们也跟基层业务法官多次沟通,他们也在帮我们不停地迭代,共同提升类案的准确度。我们期待通过业务法官的参与,实现司法与人工智能的深入融合,使人工智能更高效辅助法官审判。
来源:数据猿

未来的制造业要的不是石油,它最大的能源是数据.