一张身份证见证人工智能的进化史
前情提要
去年,谷歌的阿尔法狗战胜了韩国顶级围棋九段高手李世石,让“人工智能”一鸣惊人。国内外各种科技传媒、创业公司对人工智能的大势宣传,更是让广大吃瓜观众仿佛一觉醒来就坠入了科幻电影中的神奇场景。
实际上,任何技术发展都是一个循序渐进的过程。人工智能并没有那么神乎其神,也不是那么遥不可及,它其实早已经存在于我们周围,以增强智能的形式为我们生活中的某个环节提供便利和更加友好的体验。比如当我们在手机APP端绑定银行卡、认证个人资料时,用拍照代替手工录入,手机神奇滴识别了我们的证件类型和格式,并从中找到了它所想要的信息,这一点是否也是很智能的呢?这项看起来神奇又简单的功能背后的核心技术就是人工智能中的技术领域之一:OCR。当然你们可能会说了:“等一下,你先告诉我OCR是什么!”

图1:手机拍照证件识别
OCR(Optical Character Recognition,光学字符识别)是指利用电子设备(例如扫描仪或数码相机)采集目标字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;简而言之,就是令机器学会“识字”。
早在20世纪50年代,IBM就开始利用OCR技术实现各类文档的数字化,早期的OCR设备庞大而复杂,只能处理干净背景下的某种印刷字体。20世纪90年代,针对扫描图像印刷体文本的识别率已经达到99%以上,搭载了证件识别技术的各种文档扫描仪、名片扫描仪应运而生,一时风靡,可谓OCR应用迎来的第一个高潮。
进入21世纪,高精度拍照智能手机的诞生,催生了许多以手机拍照识别文字作进行信息录入及查询类应用。照片中的包含文字的场景复杂多变,已非传统扫描仪类应用所能比拟;而云计算及无线网络的发展,前端用摄像头进行捕捉,后端利用云计算对图片进行处理,两者结合,更让OCR应用充满了想象空间。OCR技术可谓历久而弥新,重新成为研究热点。
证件识别是OCR技术的实践应用阵地之一。身份认证是互联网+的大背景下,连接虚拟和现实的重要一环。作为服务于微信产品的模式识别团队,来自于微信支付、微信公众号审核等业务的迫切需求促使我们在证件识别领域持续钻研,不断创新。目前我们已经可以支持银行卡、身份证、机动车行驶证等多类证件自动识别,识别正确率在97%以上。本文将带领大家回顾一下证件识别技术进化的过程。
证件识别V1.0
证件识别V1.0是证件识别的奠基版本,主要服务与微信客户端的智能绑卡和身份认证。
这一版本采用带有提示框的扫描方式采集证件图像。图2的操作界面想必大家都不会感到陌生:当用户选择绑卡并用手机对准证件时,客户端首先会调起一个对焦模块,采集一帧最清晰的图像用于检测证件区域。卡片检测模块则在提示框的四个边界附近搜索稳定的边缘,并将检测到的卡片边缘用高亮表示,对用户进行提示引导。
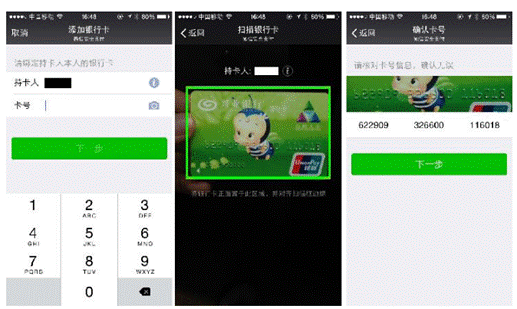
图2:微信绑卡流程
当检测到符合条件的边缘后,就可以通过计算单应性矩阵,将带有透视形变的证件区域校正成标准证件区域样本。以利于后续的信息检测和识别。
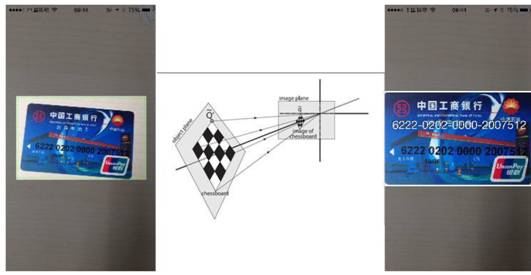
图3:证件检测与校正
V1.0的证件识别流程如图4所示。其中卡片检测及校正环节如前所述已在客户端完成。传到服务器端的标准证件区域图像仍需要:版面分析、行切分、单字切分、单字识别、后处理验证等环节才能输出最终结果。其中涉及的技术分为基于经验制定的规则策略和基于统计学习的分类模型。前者广泛应用在预处理阶段(卡片检测、版面分析、行切分、单字切分)的边缘提取、二值化、连通域分析、投影分析等,以及后处理阶段的信息验证;后者包括基于方向梯度直方图特征和多类别分类器的单字识别引擎,用于单字识别阶段。
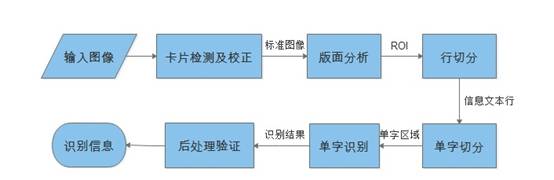
图4:证件识别流程V1.0
版面分析需要判别证件类型以及正面背面、将倒置的证件转正、提取卡片中待识别的感兴趣区域(Region Of Interest)等。由于各种卡片的版式不同,这一环节往往需要定制大量精细调节的人工规则。
得到ROI之后,需要进一步在区域内进行行切分和单字切分,得到单字区域输入给识别核心。这一步通常采用连通域分析或投影分析的方法,为了适应光照和背景等干扰,我们研发了基于模板的最优投影分割算法,可以得到较好的切分结果。

图5:基于模板的最优投影分割算法进行单字切分的结果
单字识别是体现OCR性能的核心技术。V1.0采用了基于统计学习的单字识别方法。从切分出的单字图像中提取文字的笔画、特征点、投影信息、点的区域分布等有效特征,经过融合,交给分类器。分类器将提取的待识别字符特征与识别特征库的比较,找到特征最相似的字,提取该文字的标准代码,即为识别结果。
单字识别的输出不免有误识,需要利用卡片号码校验规则、日期有效范围等先验知识对结果进行后处理,争取将正确的结果最终呈现给用户。
证件识别V2.0
V1.0版上线之后,反响不错,基本解决了产品的刚需。然而在应用过程中也暴露出一些问题:首先,版面分析的性能不稳定,主要是人工规则的叠加造成算法鲁棒性较差,case-by-case的调节很容易陷入顾此失彼的困境。其次,单字识别的误识率较高,尤其是在光线不理想或是清晰度不高的情况下识别结果较差。针对这些问题,我们引入了深度学习方法,推出了证件识别V2.0。
基于CNN回归定位的信息行检测
我们将版面分析和行切分两个依赖人工规则的预处理环节进行合并,以目标检测的思路判断图像中的卡片类型和放置方式,并直接提取卡片中的待识别信息行。这其中包含了两类任务:
检测卡片类型,将输入图像分为三种情况:卡片正面、卡片背面、非卡片;
检测信息位置和形变并校正。通用的目标检测算法只能定位目标的最小外接矩形框,不能直接判断形变类型和角度信息;我们通过回归估计得到信息行的顶点,从顶点的位置关系即可推理得到形变和角度信息,从而巧妙解决这一问题。
上述两类任务虽然属于不同类型,但是依赖的底层图像特征却可以共享。这里借鉴了人脸关键点检测的思路,采用multi-task learning,基于一个CNN网络同时输出两类任务结果:
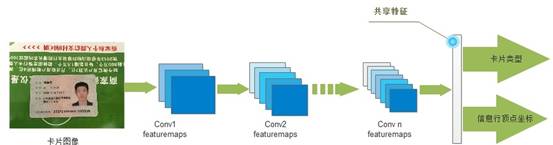
图6:基于multitask-learning的信息行检测
基于CNN的单字识别引擎
在我们之前的许多实践工作中已经证明:在样本充足的前提下,即使一个简单的CNN的单字识别性能依然可以完胜传统的特征工程模型。如果对于某些信息栏仅包含汉字(比如姓名)或者英文数字(比如证件号码或有效日期)的情况,识别性能还可以通过限定识别字符集得到进一步的提升。证件中的字形、字体和排版较为规整,我们采用包含3~4层卷积的简单CNN模型作为单字识别引擎来兼顾速度和性能需求。经过单字识别引擎的升级,单字识别性能提高了约10个百分点。
证件识别V3.0
技术的进步总是来源于产品无限追(zhe)求(teng)。基于扫描模式的证件识别方案优化之后,产品又有了新的需求:扫描的接口不够通用,能不能基于拍照、甚至直接上传照片的方式来进行证件识别呢?
听起来不是一个很过分的要求,然而实际体验之后,发现:由于客户端不再具有检测校正的机会,传到服务器的待识别对象的画风就由7A变成了7B和7C。这就引入了三个难题:
证件在图像中占比、角度不固定,可能存在较大旋转和透视形变;
证件图像背景可能比较复杂;
同一张图中可能存在多个证件对象。
这时,直接回归定位证件信息的方法效果已经不能满足实用需求。为此,我们在V3.0版中对证件信息定位模块进行了进一步改进。

图7:证件识别的各种应用模式
基于图像统计分析的证件检测模块
加入这一模块的主要目的是应对用户上传照片中存在多个证件的情况,如图7c。我们通过一系列的图像处理和投影分析操作,判别图像中证件个数,并得到单个证件的感兴趣区域(Region Of Interest, ROI),即保证每个ROI中有且只有一个证件,而且证件的区域占比超过50%。这一环节的主要难点在于:
寻找关键切点,即对应证件之间的区分位置, 需要针对背景和光照变化较为鲁棒;
需要判别证件个数,避免误切。
在算法研发过程中,我们针对各种实际情况进行了测试和调节,以保证较好的性能。

图8:证件检测模块的输出结果
基于深度学习的证件和信息定位模块
由于拍照模式下证件本身的形变可能较大,直接回归条目位置已经不能达到很好的效果。于是,我们在V2.0的信息行定位网络中加入卡片顶点检测的分支,得到证件的类型、位置和摆放角度。这些信息同时可以辅助信息行的检测和定位。由于这个模块的加入,V3.0已经可以完美支持证件的360°旋转,较大角度的透视形变,以及复杂的拍摄背景等情况。图9给出了一些实际场景中Demo示例。
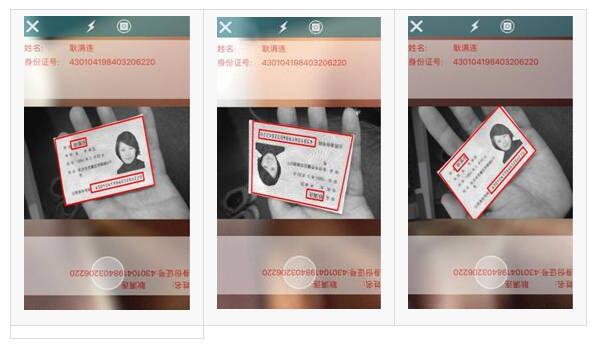
图9:支持全角度旋转和较大透视形变的证件识别
形近字识别优化
OCR的一个经典难题就是形近字的识别,这些看起来长得很像的字符经常让识别引擎“傻傻分不清楚”--即使是强悍的深度神经网络也难免挂一漏万。在V3.0中,我们引入了一个提高类别区分度的损失函数:center loss。其原理大致如下:之前的分类损失函数,如softmax loss,只关注了待识别的图像应该属于哪个类别,但是并没有关心一个同样重要的问题:同类别的样本特征是否足够聚集?
以分类界的hello world问题--“mnist手写数字识别”为例,把网络倒数第二层全连接层输出一个2维的特征向量可视化,其分布如图10A。可见,每个类别内的特征分布呈狭长条状,类内差异较大。Center loss就是给每个类别的数据定义一个center,大家要向center靠近,离得远的要受惩罚。从而把特征分布变成了图10B的样子。采用center loss,我们的单字识别引擎性能提高了约2%。
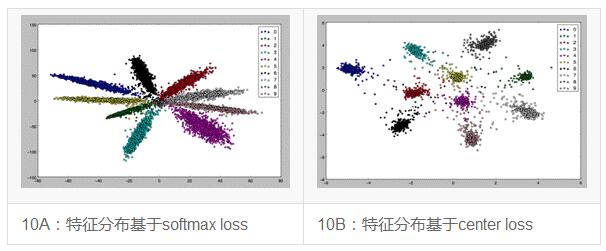
图10:center loss 示意图
训练数据的准备
所有的深度学习网络都有一个共同点:成也数据,败也数据。充足的数据燃料才能使网络的性能得到飞升。然而证件属于身份敏感信息,搜集和标注都有较大的成本。当实际样本不能满足我们的训练需求时,我们就转向合成样本的途径:通过开发各种合成样本的工具,得到大批量的接近真实情况的合成样本;采用合成样本训练、实际样本微调和测试的形式,以较为经济高效的方式达到各类网络性能的实用化水平。图11为我们为证件定位任务和单字识别任务准备的训练样本,这些合成样本已经广泛应用到了各类模型训练中。

图11:利用合成工具产生的训练样本
应用前景展望
作为人类需求牵引科技发展走到今天,智慧的延伸决定了世界的无限潜能。证件识别作为连接互联网线上和线下的重要一环,在各种互联网应用入口中承担着重要的角色。微信AI一直以来以业务需求为驱动,以实际应用为产出,在证件识别领域深入钻研,广泛实践。目前我们可以自信地说,微信AI在证件识别这一技术领域处于业界领先地位,欢迎各位同行交流探讨。
未来的制造业要的不是石油,它最大的能源是数据.